khstar
Yarn Cluster로 Spark-submit 실행시 --deploy-mode 실행 확인 본문
빅데이터 Spark 공부중입니다.
Spark 애플레케이션(jar)을 만들어서 spark-submit으로 실행하는 것을 확인 중이었는데요.
우선 코드는 아래와 같습니다.
코드 출처는 빅데이터 분석을 위한 스파크2 프로그래밍 예제입니다.
https://book.naver.com/bookdb/book_detail.nhn?bid=13483878
package com.wikibooks.spark.ch6;
import kafka.serializer.StringDecoder;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
// 6.2.4절 예제 6-11
public class KafkaSample {
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf();
JavaSparkContext sc = new JavaSparkContext(conf);
JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(3));
Map<String, Integer> topics1 = new HashMap<>();
topics1.put("kafka-example", 3);
Map<String, String> params = new HashMap<>();
params.put("metadata.broker.list", "master:9092");
Set<String> topics2 = new HashSet<>();
topics2.add("kafka-example");
JavaPairInputDStream<String, String> ds2 = KafkaUtils.<String, String, StringDecoder, StringDecoder> createDirectStream(ssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
params,
topics2);
ds2.print();
ssc.start();
ssc.awaitTermination();
}
}
자바 애플리케이션입니다. jar로 묶는 방법은 별도로 설명 안하겠습니다.
deploy-mode client
이글의 목적은 deploy-mode에 따른 실행이 다르기 때문입니다. 이것 때문에 몇일을 고생했네요.
jar 파일을 실행은 다음의 명령으로 실행 합니다.
--deploy-mode client는 생략 가능합니다. 기본 값이 client 입니다.
# spark-submit \
--class com.wikibooks.spark.ch6.KafkaSample \
--name kafkaSample \
--master yarn \
--deploy-mode client \
--driver-memory 2g \
--executor-memory 1g \
--executor-cores 1 \
../examples/jars/Java-Sample.jar
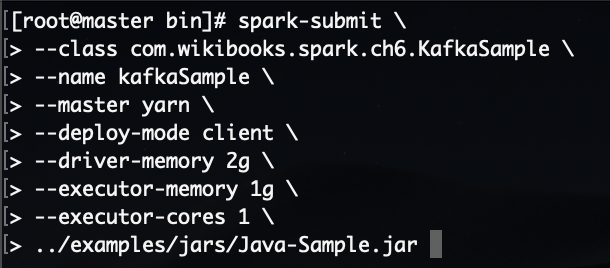
정상적으로 실행이 되면 다음과 같은 로그가 생성됩니다.

위 예제는 Kafka 스트리밍 예제입니다.
Kafka는 별도로 찾아 보시기 바랍니다.
아무튼 이렇게 실행을 해둔 상태에서
kafka-console-producer에서 다음과 같은 메시지를 보냅니다.

그럼 spark 실행 콘솔에서 다음과 같이 메시지를 받은 것을 확인 할 수 있습니다.
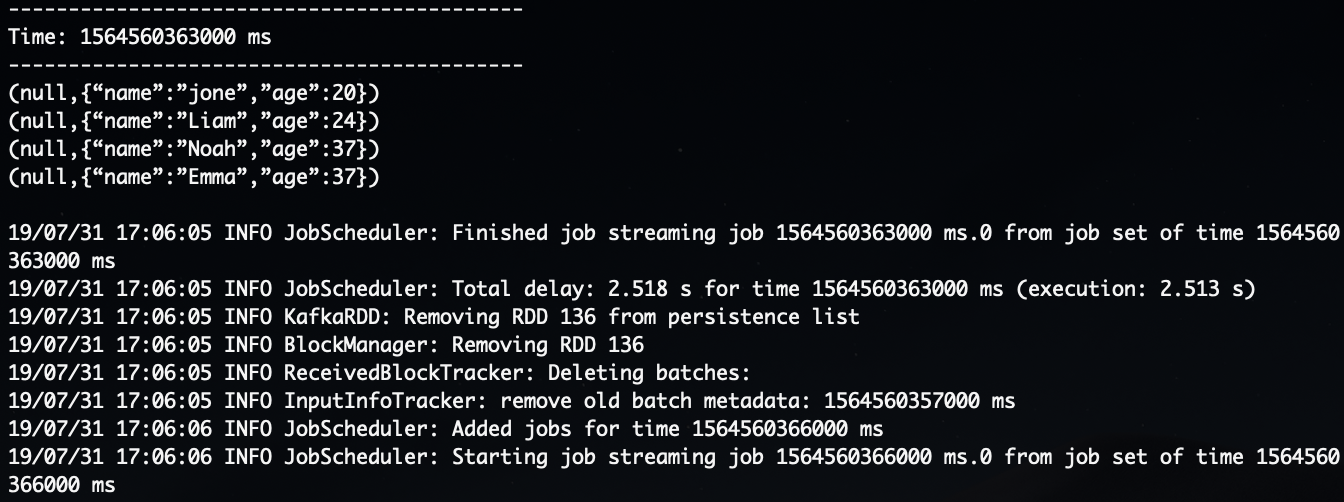
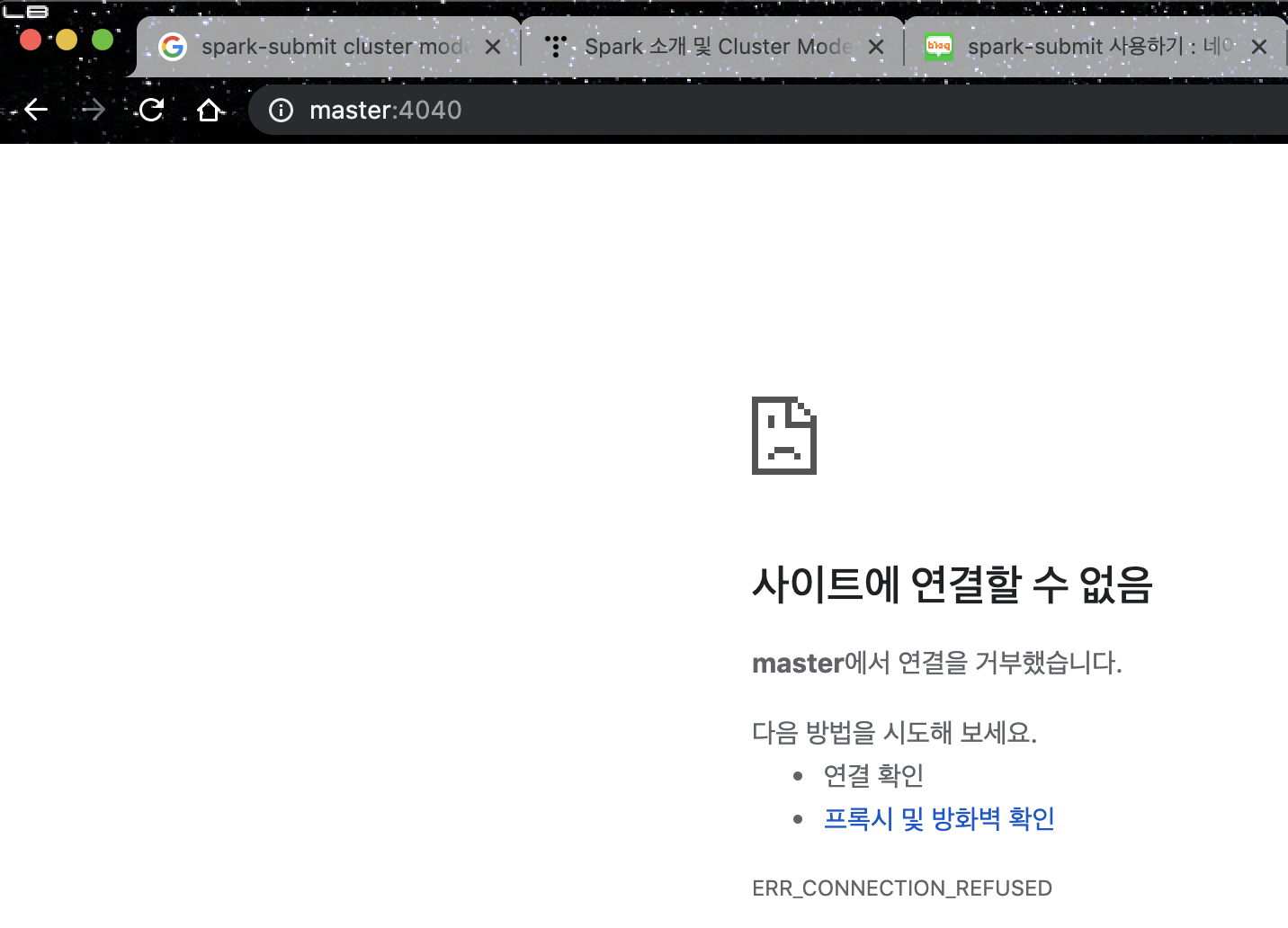
--deploy-mode client 로 실행하는 경우 실행한 서버에 4040포트(상황에 따라 다른 포트가 생성될수 도 있습니다.)가 생성됩니다.
이 4040 포트는 웹에서 spark 웹 콘솔에 접근하기 위한 포트 입니다.
크롬에서 <IP or Host>:4040으로 접속해봅니다.
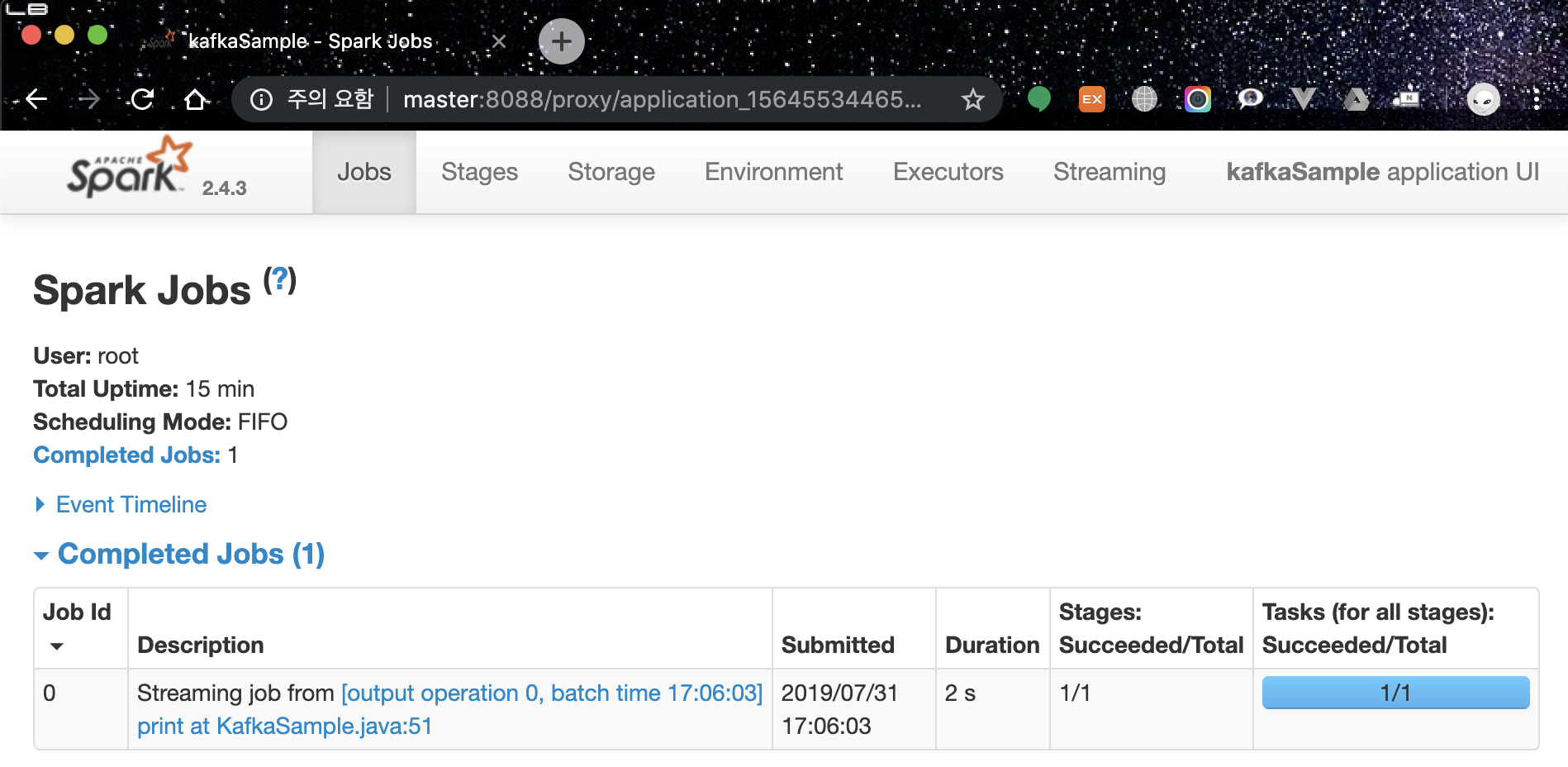
그럼 8088포트로 리다이렉트 되면서 다음과 같은 페이지를 볼수 있습니다.
spark-submit 실행 옵션은 다음 링크를 확인해 주세요.
deploy-mode cluster
그럼 다음은 --deploy-mode cluster 모드로 실행하는 경우를 살펴보겠습니다.
위의 명령어에서 --deploy-mode만 cluster로 바꿔주면 됩니다.
# spark-submit \
--class com.wikibooks.spark.ch6.KafkaSample \
--name kafkaSample \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 1g \
--executor-cores 1 \
../examples/jars/Java-Sample.jar

--deploy-mode cluster 로 실행하게 되면 다음과 같이 계속 (state: RUNNING) 로그가 계속 출력되는 것입니다.
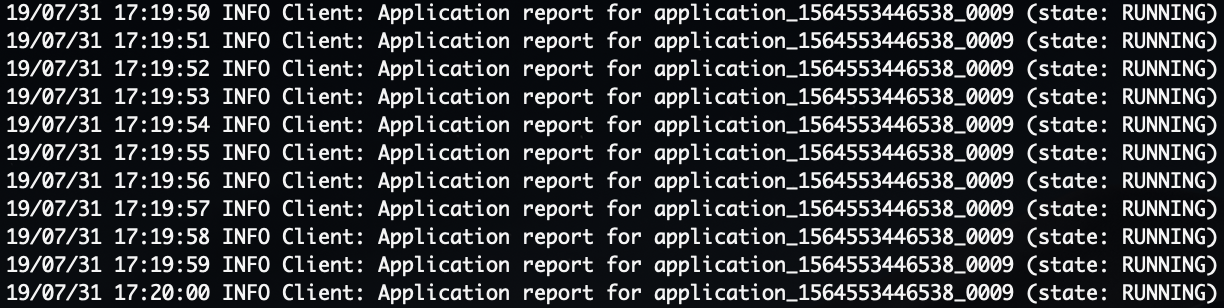
ㅜㅜ 저는 이게 정상 실행이 아니라고 생각해서 이게 왜이러나 계속 찾아 봤습니다.
근데 이게 정상 실행 상태였습니다.
그럼 실행을 확인해 보겠습니다.
웹에서 <IP or Host>:8088 포트로 접속합니다.
그럼 다음과 같이 hadoop cluster 콘솔을 확인할 수 있을 것입니다.
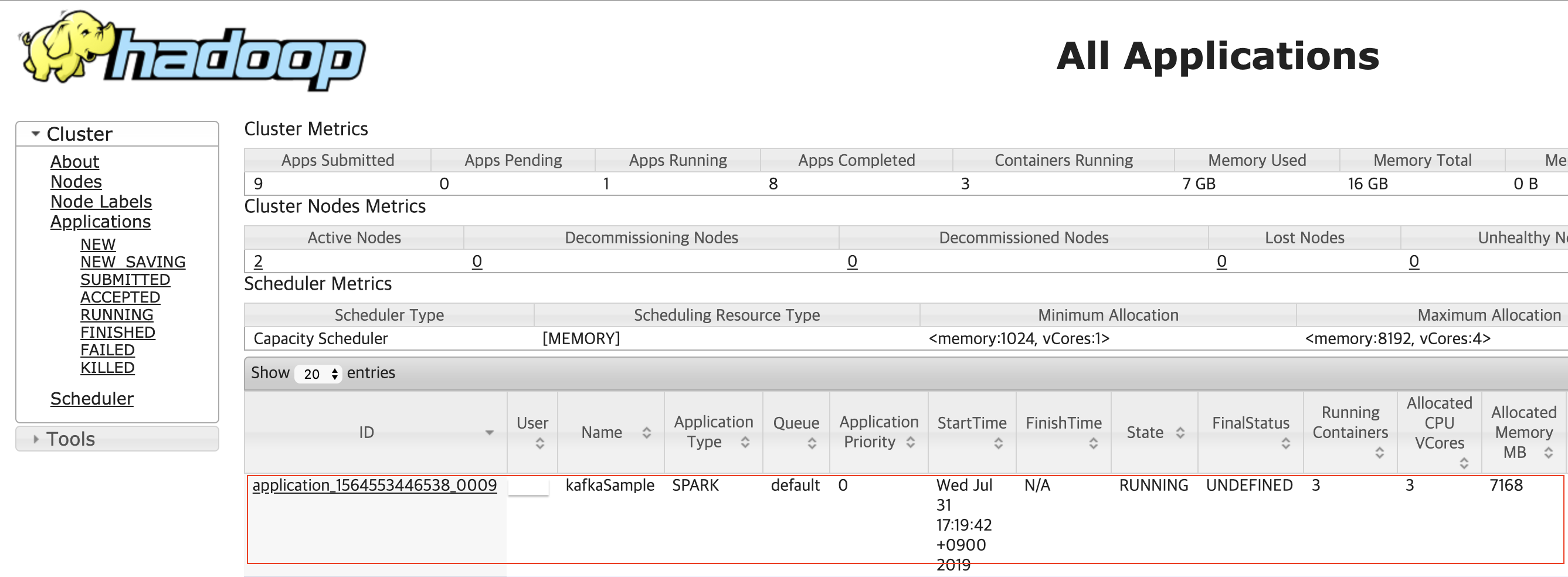
빨간 박스가 현재 실행한 spark-submit 입니다.
ID 부분의 링크를 클릭합니다.

그럼 다음과 같은 화면이 나옵니다. 애플리케이션 정보입니다.
맨 밑에 보면 Node 정보가 보입니다.
Node에서 Logs를 클릭해본니다.
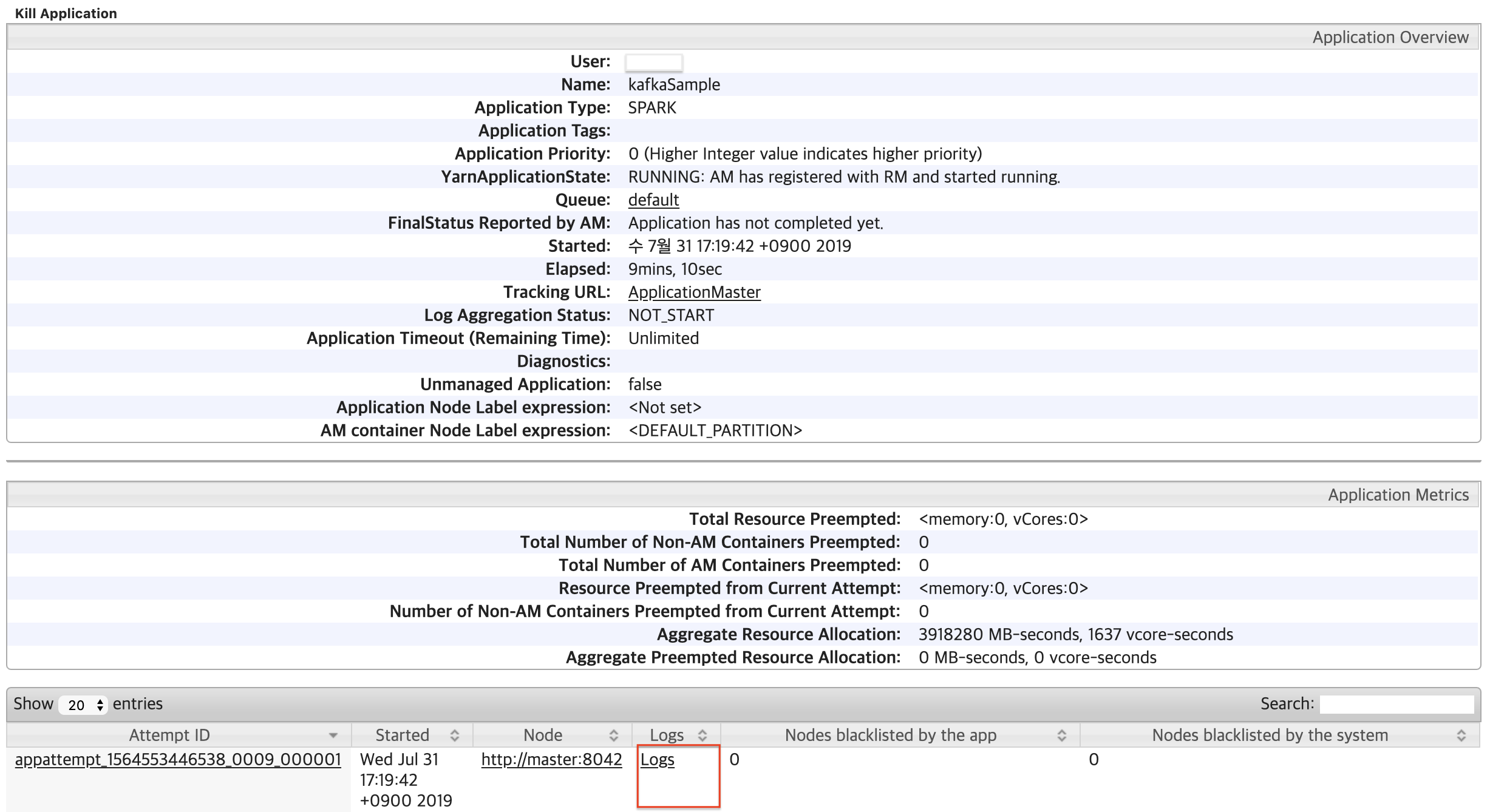
그럼 다음 화면이 나옵니다.
여기서 stdout을 클릭합니다.
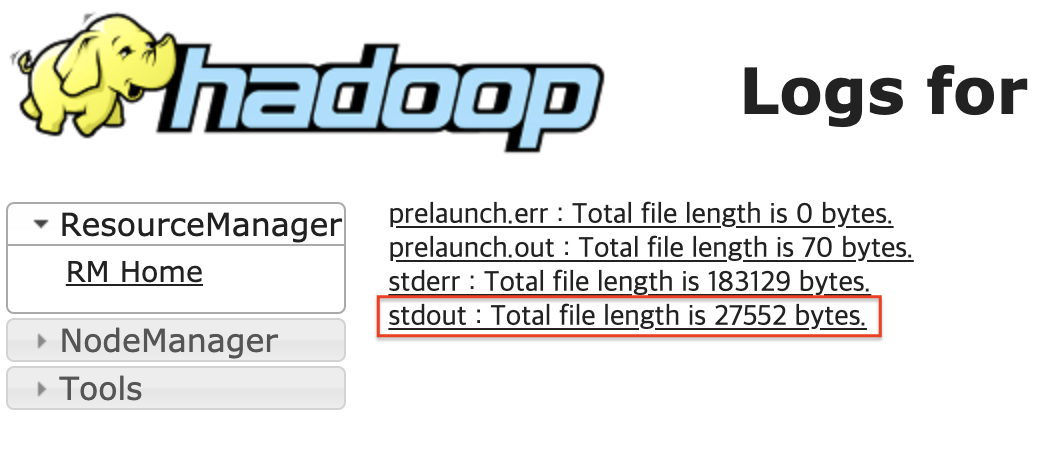
여기서 client 모드의 터미널에서 확인했던 Time 로그를 볼수 있습니다.

이제 kafka-console-producer에서 메시지를 다시 보내면 여기서 로그를 확인 할 수 있습니다.

client 모드에서 생성되는 4040포트는 yarn cluster 모드에서는 생성이 안됩니다.
이 경우 앞의 애플리케이션 정보에서 접근이 가능합니다.
애플리케이션 정보 화면에서 Tracking URL의 링크를 클릭합니다.

그럼 spark 웹 콘솔을 볼수 있습니다.
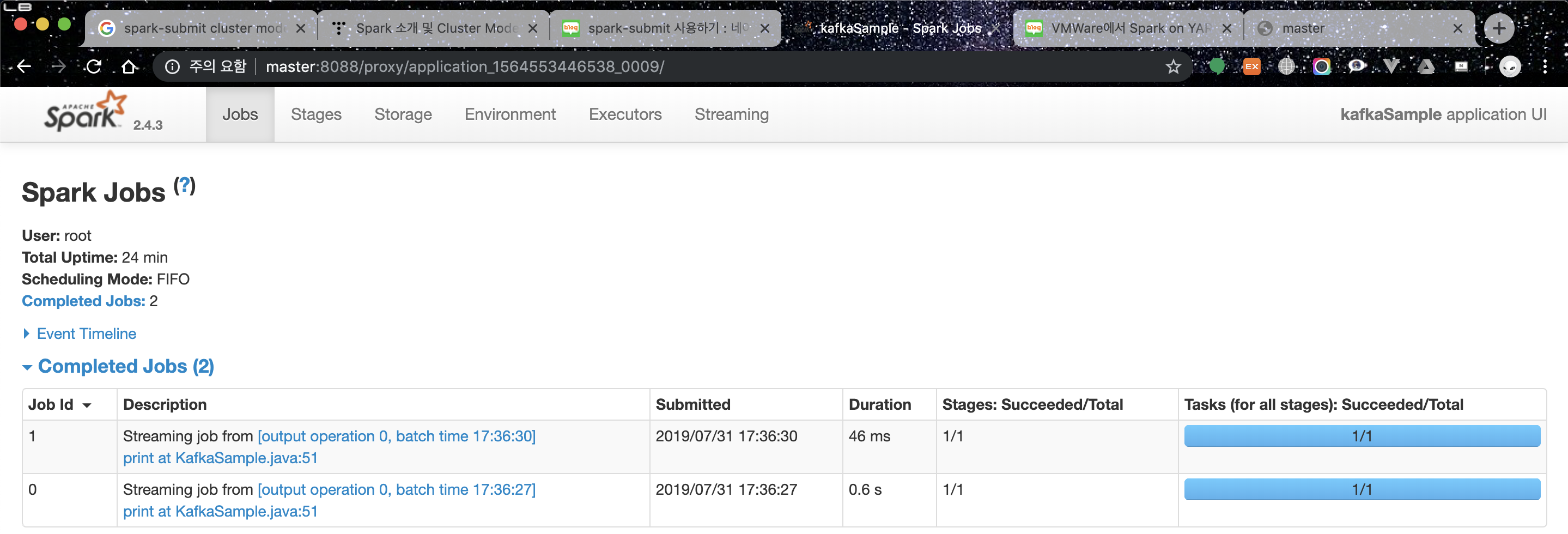
spark 콘솔에 Streaming 메뉴는 Spark Streaming Application을 실행한 경우에만 생성됩니다.
이점 참고해주시고요.
주의 :
cluster 모드에서 애플리케이션을 종료하는 경우 kill -9 PID로 종료를 하는 경우
cluster이기 때문에 다른 노드에서 프로세스가 살아나게 됩니다. (맞나?? ㅜㅜ) 아무튼 저는 프로세스가 정상 종료 되지가 않았습니다.
cluster모드의 경우 앱 종료 역시 hadoop 웹 콘솔의 애플리케이션 정보에서 kill Application을 클릭해서 애플리케이션을 종료할 수 있습니다.
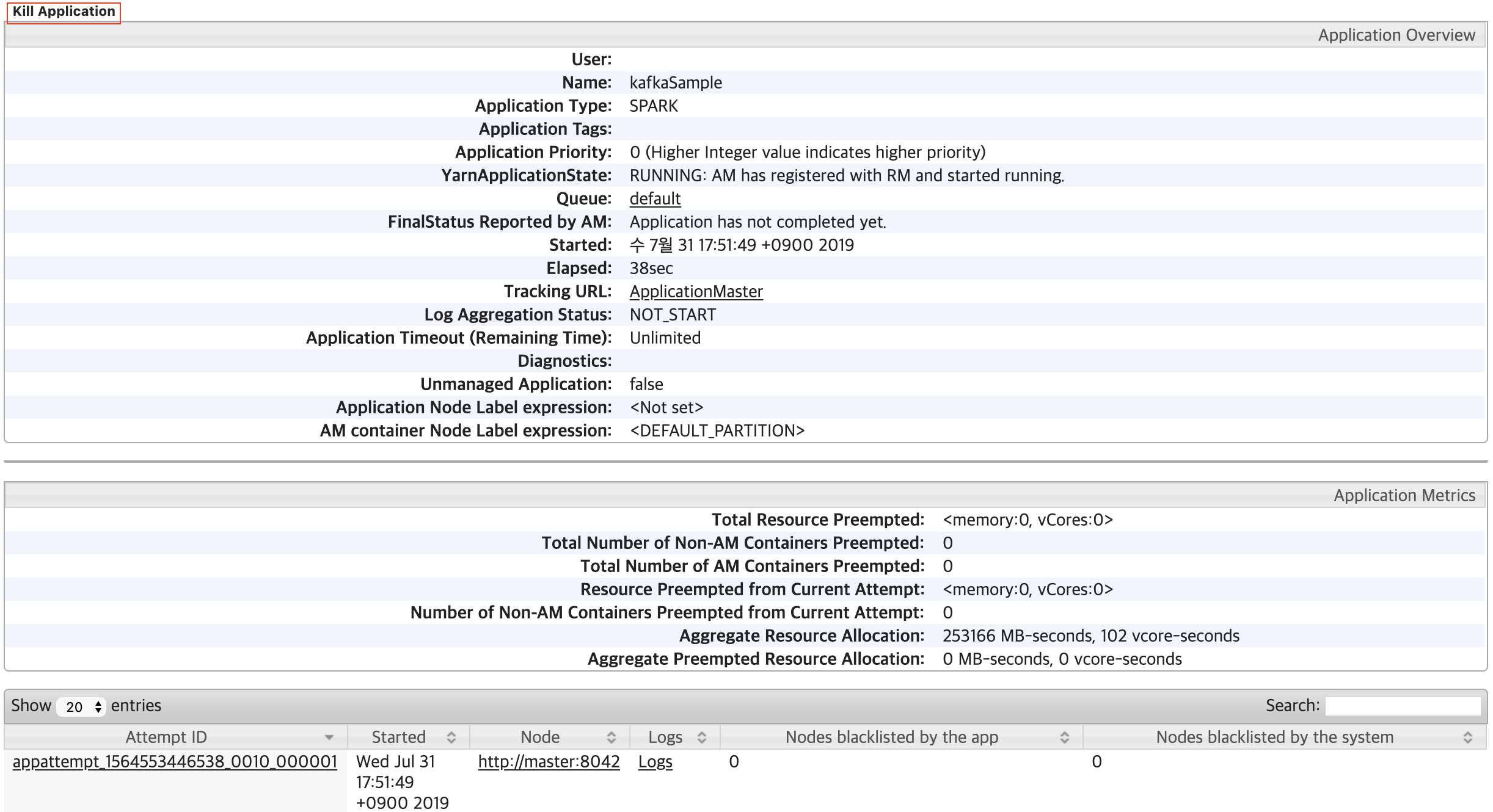
참 글을 두서없이 써서 보시기 힘드실것 같습니다.
이해 부탁드리며 제가 헤딩을 엄청하는 스타일이라 잘못된 정보나 수정사항이 있으면 알려주세요.
참고
빅데이터 분석을 위한 스파크2 프로그래밍 : https://book.naver.com/bookdb/book_detail.nhn?bid=13483878
빅데이터 분석을 위한 스파크 2 프로그래밍
스파크를 처음 접하는 입문자를 위한 안내서!하둡으로 대표되던 빅데이터 처리 기술은 빅데이터와 머신러닝, 딥러닝의 붐을 타고 믿을 수 없을 만큼 빠른 속도로 발전해가고 있습니다. 작년 봄 이 책의 초판이 출시되던 해에 스파크는 이미 최고의 데이터 처리 플랫폼 중 하나로 인정받고 있었습니다. 하지만 더 이상 큰 폭의 개편은 없을 것만 같았던 스파크는 그 후로도 더욱 주목할 만한 변화를 거듭하면서 불과 1년이 지난 지금 더욱더 새로워진 API와 고도화된 성능을
book.naver.com

